
RAG vs. Context Extins: Nu Face Această Greșeală în Sistemele Tale AI
Timp de câțiva ani, RAG (Retrieval Augmented Generation) a fost soluția standard pentru a conecta modelele AI la date externe. Astăzi, lucrurile se schimbă — și merită să înțelegem de ce.
De ce a apărut RAG-ul în primul rând?
Orice model de limbaj are o limitare fundamentală: cunoștințele sale sunt “înghețate” în momentul antrenării. Odată finalizat procesul de training, modelul nu mai învață automat despre evenimente noi sau despre datele interne ale companiei tale.
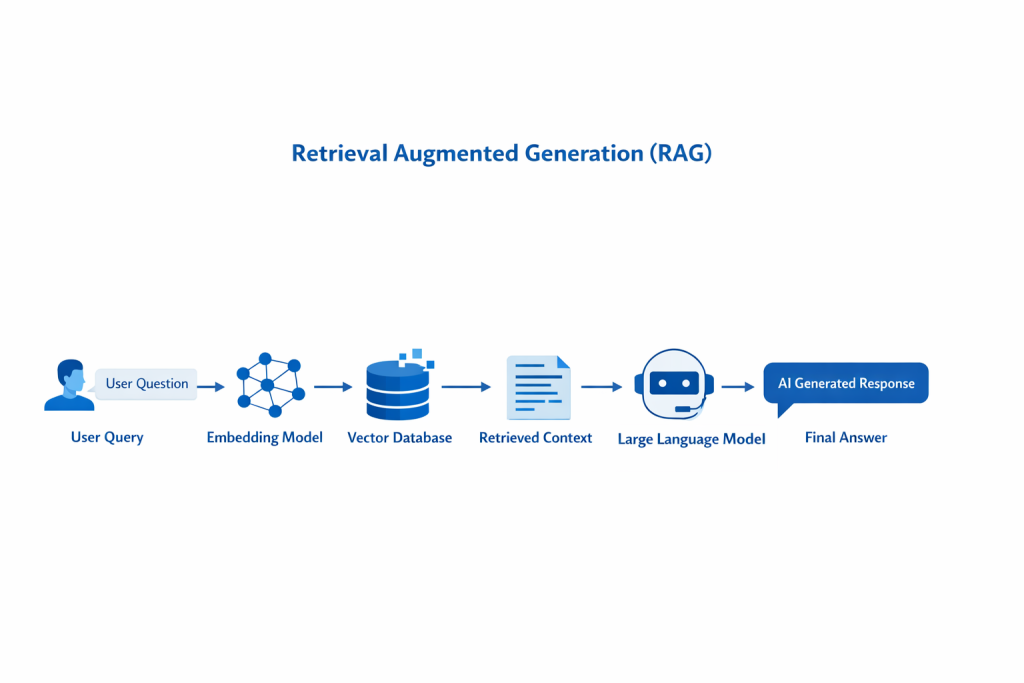
Aceasta a ridicat o problemă practică pentru oricine construia aplicații AI reale: cum oferi modelului informația potrivită, exact când are nevoie de ea?
Răspunsul dominant a fost RAG — un mecanism prin care sistemul preia fragmente relevante din surse externe și le inserează direct în prompt. Această abordare a ajuns să susțină aplicații majore, de la motoare de căutare enterprise (precum Glean) până la funcționalități din Microsoft Copilot.
Ce se schimbă acum: ferestrele de context uriașe
Una dintre cele mai semnificative evoluții din ultimul an este extinderea dramatică a ferestrelor de context. Primele modele puteau procesa câteva pagini de text. Astăzi, Claude de la Anthropic suportă aproximativ 200.000 de tokeni, iar Gemini 1.5 a introdus o fereastră de 1 milion de tokeni.
La această scară, devine posibil ceva ce anterior era exclus: în loc să extragi fragmente dintr-un document, poți pur și simplu să dai modelului întregul document și să îl lași să identifice singur ce contează. Un contract legal complet, o specificație tehnică detaliată, chiar o carte întreagă — toate pot fi procesate dintr-o singură rulare.
Întrebarea evidentă devine atunci: dacă modelele pot citi totul direct, mai avem nevoie de RAG?
Limitele abordării bazate pe context extins
La prima vedere, arhitectura bazată pe context lung pare extrem de atractivă: renunți la pipeline-uri de embedding, baze de date vectoriale și logică de retrieval. Modelul citește totul și decide singur ce e relevant.
Dar în practică, această abordare vine cu provocări serioase:
Problema eficienței. Imaginează-ți un sistem care răspunde la întrebări despre un manual tehnic de 500 de pagini. Cu context lung, modelul trebuie să proceseze întregul manual la fiecare interogare. RAG funcționează diferit: documentele sunt indexate o singură dată, iar ulterior sistemul recuperează doar secțiunile cu adevărat relevante pentru întrebarea pusă.
“Acul în carul cu fân”. Faptul că o informație există undeva într-o fereastră uriașă de context nu garantează că modelul o va găsi. Pe măsură ce promptul crește, atenția modelului se poate dilua. Un paragraf important îngropat în sute de pagini poate fi ratat. Sistemele de retrieval abordează tocmai această problemă, reducând spațiul de căutare înainte ca modelul să înceapă să raționeze.
Problema de scară. Chiar și un milion de tokeni reprezintă o cantitate infimă față de datele pe care le gestionează organizațiile mari. Baze de cunoștințe enterprise, documente interne, log-uri, repository-uri de cod — acestea pot depăși cu ușurință terabytes sau chiar petabytes. În aceste medii, un strat de retrieval rămâne practic inevitabil.
O a treia direcție: învățarea continuă
Există și o altă abordare care câștigă teren în cercetare: în loc să alimentezi constant modelul cu date externe, îl faci capabil să-și actualizeze cunoștințele în timp. Echipe de la Google DeepMind, Meta AI și diverse laboratoare academice studiază metode prin care modelele să integreze informații noi fără a fi reantrenate de la zero.
Dacă această abordare va funcționa la scară, modelele ar putea evolua continuu odată cu lumea, în loc să depindă de pipeline-uri externe de date. Deocamdată însă, aceasta rămâne în mare parte un subiect de cercetare. Sistemele de producție reale continuă să se bazeze pe retrieval, într-o formă sau alta.
Ce înseamnă toate acestea pentru tine, ca profesionist în vânzări B2B?
RAG nu a fost niciodată singurul răspuns — a fost pur și simplu cel mai practic mod de a conecta un model la informații externe. Contextul extins nu îl înlocuiește, ci îl completează.
Probabil că viitorul nu aparține unei singure abordări, ci combinării lor inteligente în funcție de context:
• Context extins — când lucrezi cu un singur document lung (un contract, o ofertă complexă, un caiet de sarcini).
• RAG — când ai o bază de cunoștințe mare și vrei răspunsuri precise, fără să procesezi totul de fiecare dată.
• Sisteme hibride — combinând retrieval inteligent cu ferestre mari de context pentru cazuri complexe.
Provocarea reală nu este tehnică — este strategică: să știi care instrument potrivit, la momentul potrivit, pentru problema ta specifică.
Ți-a fost util acest articol? Abonează-te la newsletter pentru a primi săptămânal idei practice despre AI, Excel și vânzări B2B.
adrianorbai.ro | Vânzări B2B · Excel pentru Vânzări · AI Tools